Le mixage de la voix est probablement l’un des aspects les plus compliqués du mixage audio.
Tout simplement parce que nous sommes bien plus sensibles au réalisme d’une voix dans un enregistrement qu’au réalisme d’une guitare électrique ou d’une batterie.

Lorsque j’ai commencé à mixer mes propres morceaux, j’avais beaucoup de mal à comprendre ce qu’il fallait faire et pourquoi. Quel traitement ajouter, quel réglage appliquer à tel ou tel effet.
J’ajoutais des plugins en suivant les conseils que j’avais pu lire ou entendre, mais sans comprendre l’impact que cela avait sur le mix.
Tout ceci me semblait assez mystérieux, en fait, …
… car je ne maîtrisais pas les étapes essentielles au mixage d’une voix.
Parce qu’effectivement, s’il n’existe pas de règles pour réussir un mixage de voix, il y a tout de même un certain nombre d’étapes standards qui sont presque inévitables. Et ce, que vous fassiez votre mixage sur FL Studio, Cubase ou n’importe quel autre DAW.
Voici donc, à travers cet article, un aperçu détaillé et “pas-à-pas” de ce qu’il faut faire lorsque l’on commence à mixer une piste de voix lead.
Etape 1 : Définissez une cible
La plus grosse erreur que vous pourriez faire concernant le mixage vocal, c’est de vous lancer sans avoir défini un son cible.
Je dirais même, c’est d’aller appliquer des conseils que vous avez entendu à droite à gauche, sur Internet ou pas, sans avoir réfléchi à leur pertinence dans votre mix.
“Compressez avec un ratio de 6:1 et une attaque de 15 ms.”
“Ajoutez un égaliseur et coupez de -5 dB avec un filtre en cloche à 1200 Hz”
…tous ces conseils sont à prendre avec des pincettes car :
- ils ne sont applicables qu’au morceau / au mixage de la personne qui les donne puisqu’ils dépendent à 100% du signal sonore enregistré ;
- ils vont nécessairement varier selon le genre musical : on ne compressera absolument pas de la même façon une voix pour le jazz, pour la variété ou pour le hard rock.
C’est la raison pour laquelle vous ne trouverez sur Projet Home Studio presque aucun chiffre, aucun “réglage pour bien mixer la voix”, mais seulement des lignes directrices.
Mais du coup comment faire ?
Eh bien, la première chose à faire avant de mixer une piste de voix, c’est de se poser la question du son que l’on souhaite.
Recherchez-vous un son agressif, frontal ?
Ou bien au contraire quelque chose de doux et aérien, avec beaucoup de variations dynamiques ?
Votre morceau s’accommoderait-il mieux d’une voix très sèche ou au contraire de quelque chose avec beaucoup de réverbe ?
Prenez le temps de réfléchir à ce type de questions pour définir votre son de voix cible — si besoin, trouvez un morceau de référence qui ressemble à ce que vous voulez faire.
Cela vous permettra de mixer votre voix en ayant un objectif clair, qui correspondra à votre morceau.
Etape 2 : Préparez votre piste de voix avant le mixage
Généralement, lorsque l’on pense au mixage de voix lead, on pense tout de suite aux plugins que l’on va ajouter.
C’est normal : c’est la partie la plus amusante du mixage.
Pourtant, avant de commencer à ajouter des effets quels qu’ils soient, il est vraiment important de préparer correctement sa piste de chant.
Si l’on part du principe que l’enregistrement est de bonne qualité, cette “préparation” va se traduire par deux grandes actions : le comping et l’édition.
Le comping
Généralement, pour une même ligne de chant, vous allez faire plusieurs prises.
Dans les années 60, beaucoup de morceaux étaient faits en “one take” (une prise), notamment parce que les enregistrements étaient faits sur bandes magnétiques.
Aujourd’hui, la technologie et les capacités de stockage de nos PC permettent d’effectuer facilement trois ou quatre prises pour un même morceau.
Conséquence immédiate : pour une ligne de chant donnée, vous allez pouvoir sélectionner les meilleurs passages et les combiner.
Par exemple, si la 1ère phrase est meilleure sur la prise A que sur la prise B, vous allez garder la prise A. Et ainsi de suite pour chaque phrase, chaque couplet… jusqu’à ce que vous obteniez une piste complète et parfaite !
Peut-être avez vous l’impression que c’est un peu tricher. Je vous rassure : cette technique, que l’on appelle comping, est utilisée par la plupart des studios professionnels.
Sauf dans le cas du tube My Heart Will Go On, mais tout le monde n’est pas Céline Dion ! 😉
Prenez-donc le temps de faire plusieurs prises et compilez-les en une seule piste.
Astuce : pour vous aider à sélectionner les parties de votre morceau, vous pouvez utiliser une comp sheet comme celle-ci en notant les meilleurs passages :

L’édition
Même sur de très bonnes prises de son, il y a toujours des choses que l’on ne souhaite pas garder, tels que des bruits de respiration ou bien la repisse du casque dans le microphone lors de passages calmes.
En contexte home studio, suivant les conditions dans lesquelles vous enregistrez, cela peut être bien pire :
- bruit de fond de l’ordinateur ;
- bruit de fond de la clim ;
- un oiseau ou une voiture dehors ;
- …
Lorsque le chanteur ou la chanteuse chante, ce type de bruit est généralement couvert, donc ça ne pose pas trop de problème (mais éteignez tout de même votre clim lorsque vous enregistrez…).
Par contre, sur les passages calmes entre les phrase ou les couplets, il faut absolument supprimer ces anomalies, au risque qu’elles ressortent encore plus lors du mixage à cause de la compression.

Pour ce faire, il vous suffit simplement :
- de découper les passages que vous ne souhaitez pas garder en utilisant l’outil adéquat de votre DAW ;
- puis d’ajouter de rapides fondus au début et à la fin de chaque stem audio pour éviter que des clics numériques apparaissent.
Au final, vous obtiendrez donc une piste de voix la plus propre possible, qui sera plus facile à mixer.
Etape 3 : Gain staging
Une fois que votre piste a été correctement éditée, c’est généralement le bon moment pour aller ajuster le niveau des phrases ou syllabes.
Autrement dit, pour faire une sorte de gain staging.
Cette étape est super importante car elle va vraiment faire la différence entre un mix amateur et un mix pro.
Du moins en ce qui concerne le mixage des voix lead.
Imaginons que vous ayez une piste de chant avec des passages doux et des passages forts :

Si vous laissez la piste comme ça et que vous essayez de la compresser, vous allez rencontrer le soucis suivant :

- si vous compressez avec un seuil élevé, seuls les passages forts vont être affectés ;
- mais si vous abaissez le seuil pour prendre en compte les passages de faible niveau, les passages forts vont se retrouver complètement écrasés par la compression car ils seront bien au-dessus du seuil .
Par contre, en ajustant phrase par phrase, vers par vers, voire syllabe par syllabe le niveau de la piste, vous allez éviter des problèmes lors de l’ajout d’effets et vous pourrez vous assurer que chaque mot soit intelligible dans le mix.
Il n’est pas toujours nécessaire d’aller jusqu’à la syllabe, mais assurez-vous tout de même qu’en moyenne les phrases soient au bon niveau.
Pour cela, vous pouvez soit utiliser un plugin de gain simple avec une courbe d’automation, soit utiliser un plugin de réglage automatique de gain comme le Vocal Rider de Waves.
A noter que ce dernier peut générer une courbe d’automation automatiquement, que vous pourrez si besoin éditer manuellement pour être un peu plus précis.
Etape 4 : Egalisation soustractive
La plupart du temps, la première chose que vous allez devoir faire lors du mixage d’une voix lead, c’est la nettoyer en utilisant l’égalisation.
Ou plus précisément, corriger les fréquences qui ne vous semblent pas agréables.
Typiquement, on va souvent retrouver des grondements dans les basses, en-dessous de 50-100 Hz, qui vont plus correspondre à des bruits de fond (électriques, extérieurs…) qu’à la voix en elle-même.
Tout celà, vous pouvez le retirer ou l’atténuer facilement avec des filtres passe-haut (ou low-shelf).
Ensuite, il va falloir corriger les autres problèmes de fréquences que vous entendez.
Ceux-ci peuvent être liés à toutes sortes de causes plus ou moins maîtrisables telles que :
- l’acoustique de la pièce où vous enregistrez (sans traitement acoustique, vous pouvez par exemple subir l’effet de résonances modales) ;
- des fréquences un peu dures à l’oreille liées à la construction du microphone et/ou à la qualité du préampli ;
- des fréquences un peu gênantes de la voix qui ressortent plus avec un microphone qu’avec un autre (cela dépend des chanteurs/chanteuses) ;
- la qualité de la performance du chanteur / de la chanteuse.

Pour corriger ces problèmes, le plus simple est d’utiliser la technique usuelle d’égalisation classique :
- Identifiez le problème ou l’élément que vous souhaitez corriger
- Ajoutez un filtre EQ en cloche avec
- un facteur Q relativement élevé (4 à 10)
- une amplification élevée (+10 dB par exemple)
- Parcourez lentement le spectre de fréquences avec ce filtre jusqu’à ce que vous entendiez le problème ressortir de façon forte (sous forme de résonance, par exemple)
- Atténuez le signal (au lieu des +10dB) au niveau de la bande de fréquences sur laquelle vous vous trouvez en ajustant au besoin le facteur Q
J’insiste en particulier sur le premier point : prenez le temps d’écouter d’abord votre piste pour identifier les éléments qui vous gênent. En effet, le mixage des voix a beau être quelque chose de précis, il est inutile d’aller corriger de minuscules problèmes qui ne s’entendent pas au global, mais qui seraient mis en valeur à cause du filtre à +10 dB…
Une fois cette étape achevée, votre EQ va peut-être ressembler à ça (mais peut-être à quelque chose de complètement différent, puisque ça dépend toujours du signal source) :

Notez au passage que l’on parle bien d’une égalisation pour une voix lead. Si par exemple vous mixez des chœurs, l’égalisation sera sans doute très différente.
Etape 5 : De-Esseur
Certaines lettres ou syllabes ont tendance à ressortir de façon agressive dans les aigus une fois enregistrées par un microphone.
Typiquement, il s’agit des sons comme la consonne “S” mais aussi des “F”, des “T” ou des “CH”.
C’est un phénomène audio qu’on appelle pour généraliser la sibilance et qui peu apparaître de façon plus ou moins forte selon le microphone et la forme de la bouche du chanteur/de la chanteuse.
Le fait que ces sons ressortent peut avoir un certain nombre de conséquences peu agréables pour votre mix : d’une part cela va être vite énervant pour l’auditeur, mais cela va également nuire aux effets de réverbe que vous allez ajouter après-coup, qui sont eux très sensibles à ces sons.
Ecoutez par exemple l’effet des “S” sur la texture de la réverbe dans cet exemple :
Il est donc important de contrôler au maximum ce phénomène de sibilance.
Certes, il existe des astuces d’enregistrement de voix qui permettent de minimiser la chose, mais bien souvent il va vous falloir traiter le problème dans le mixage.
Malheureusement, il est impossible d’utiliser un simple égaliseur pour couper le signal dans les 4 ou 5 kHz : si vous coupez en permanence, cela va affecter la totalité de la piste et la voix va être bizarre.
La solution, c’est donc d’utiliser ce qu’on appelle un de-esseur comme le Pro-G de Fabfilter (ou l’une de ces alternatives gratuites):
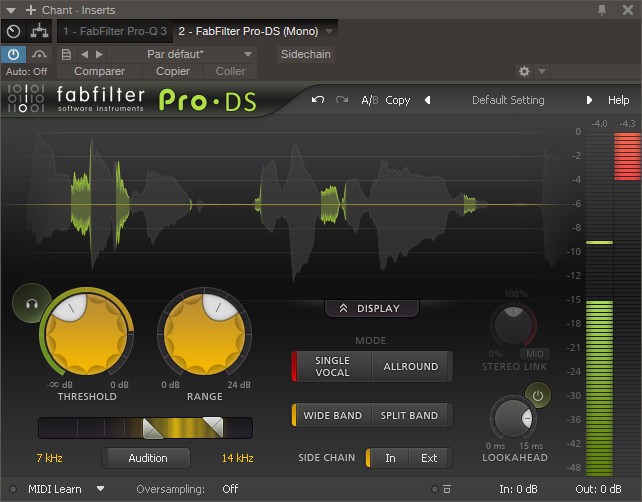
Par le biais d’un algorithme multibande, cet effet va vous permettre de contrôler la sibilance en atténuant uniquement certaines fréquences lorsque des sons type “S” sont détectés.
Donc, sans affecter les fréquences qui ne sont pas concernées par le problème.
Attention toutefois à ne pas régler le plugin de façon trop extrême, au risque de dégrader le signal : quelques décibels de réduction de gain (GR) devraient suffire dans la plupart des cas.
Etape 6 : La compression, inévitable pour le mixage des voix
Le signal étant désormais nettoyé, vous allez pouvoir passer à la compression de la piste de voix.
Parfois, vous n’aurez pas besoin de compression. Peut-être parce que le genre musical ne s’y prête pas, ou bien parce qu’il y a déjà eu une compression analogique lors du tracking.
Ceci dit, 99% du temps, les enregistrements de voix ou de chant s’avèrent être assez dynamiques : certaines phrases, certaines syllabes vont ressortir tandis que d’autres vont être moins en avant.
Conséquence : impossible de faire ressortir correctement tous les mots de façon intelligible dans le mixage. Autrement dit, si vous essayez d’ajuster le fader de volume de votre piste de voix, vous n’allez pas réussir à trouver de réglage qui convienne : par moment la piste sera trop forte et vous aurez envie de baisser le fader, et à d’autres moments les paroles seront noyées dans le mix et vous aurez envie de monter le fader.
C’est un signe que votre piste a besoin de compression pour que sa plage dynamique soit réduite.
Ajoutez donc le compresseur de votre choix sur la piste (pour débuter, celui inclus par défaut dans votre DAW peut être un bon point de départ) et réglez-le pour niveler votre piste :

La quantité de compression que vous allez appliquer, qui correspond à la réduction de gain (Gain Reduction ou GR), va dépendre du style musical : sur de la musique acoustique ou du jazz, vous allez sans doute viser un effet minimal, tandis que sur du rap ou du heavy metal vous aurez besoin d’une voix beaucoup plus frontale, beaucoup plus “rentre dedans”.
Ceci dit, l’objectif est tout de même que l’effet de compression soit le moins audible possible, puisque la compression peut générer des artefacts audio (typiquement, un effet de pompage).
Si un seul compresseur ne suffit pas à homogénéiser le niveau de la piste de voix, n’hésitez pas à en utiliser deux à la suite pour traiter différents aspects de la piste (rendez-vous sur mon guide sur la compression de la voix pour plus d’explications).
Etape 7 : Egalisation additive
Après la compression, c’est généralement le bon moment pour ajouter un EQ qui va travailler de façon additive, c’est-à-dire avec des réglages de gain positifs.
L’idée, c’est que maintenant que vous avez retiré les problèmes du signal grâce à l’égalisation soustractive (ou à l’éventuel de-esseur) et que la dynamique est correctement contrôlée par la compression, vous allez affiner la réponse en fréquences en amplifiant ce que vous voulez ou avez besoin d’entendre plus.
Autrement dit, vous allez améliorer le mix de votre piste de voix en sculptant votre son.
A vous de voir les fréquences à booster et la quantité de gain à appliquer, mais par exemple il est courant d’amplifier un peu les basses pour donner plus de corps à la voix ou de soulever les aigus pour au contraire donner de l’air et aider la voix à trancher dans le mix.
Voici un exemple de morceau où les aigus sont poussés à l’extrême (pas très agréable, mais bon…) :
Ce qui m’amène à un point d’attention : certes, je n’aime pas trop donner de règle ultra-précise, mais si vous vous rendez compte que votre égalisation dépasse les +5 ou +6 dB, posez vous la question “est-ce que ce que je fais a du sens ?”.
Autant sur une batterie, ça peut facilement se comprendre, autant dénaturer une piste de voix peut être très rapide — c’est pourquoi il est nécessaire d’être prudent.
Exemple : plutôt que de booster les aigus à +15 dB, peut-être le mix au global est-il trop fort dans les aigus ? Dans ce cas, réduisez plutôt les aigus sur d’autres pistes plutôt que de dénaturer la piste de voix… 😉
Etape 8 : Saturation (optionnel)
C’est complètement optionnel, mais il peut parfois être intéressant d’ajouter de la saturation harmonique.
Il peut s’agir de saturation poussée au maximum pour générer un effet spécial type distorsion, mais par défaut je vous conseille plutôt de rester dans des réglages de saturation plus subtils.
L’idée, c’est de renforcer le contenu harmonique du signal pour rendre le son un peu plus chaud, un peu plus intéressant, un peu plus remarquable dans le mix.
Notez au passage que cette technique n’est pas spécifique au mixage des voix : elle peut être appliquer sur toutes sortes d’instruments.

Bien sûr, si la prise de son a déjà été effectuée avec un préampli coloré (type Neve par exemple), ajouter à nouveau de la saturation risque de ne pas apporter grand chose — voire même nuire à la qualité du mix.
Par contre, si le préampli utilisé est neutre (ce qui est le cas de la plupart des préamplis intégrés aux cartes sons) voire a tendance à donner un rendu plutôt plat, alors ça vaut sans doute le coup d’ajouter un peu de saturation cosmétique, grâce à des plugins simulant des bandes magnétiques par exemple.
Quelques recommandations de plugins :
- Kazrog True Iron ;
- Waves J37 (-10% avec ce lien et le code qui s’affiche) ;
- Soundtoys Radiator ;
- ou par exemple l’un de ces plugins de saturation gratuits.
Etape 9 : Compression parallèle (optionnel)
Bien entendu, toutes sortes de traitements peuvent être appliqués aux voix.
L’objectif de cet article n’est donc pas de lister la multitude de possibilités existantes — sinon vous seriez tout simplement perdu(e) au milieu de toutes ces informations (sachant qu’il y en a déjà beaucoup sur cette page 🙂 ).
Toutefois, une technique à la fois très pratique et couramment utilisée est celle nommée “compression parallèle” ou encore “New York Compression”.
Cette méthode consiste à compresser fortement une piste identique à la piste de voix de base puis à la remixer subtilement avec le signal d’origine.
Cela permet du coup de garder les crêtes et une partie de la dynamique du signal mais en venant soutenir “par le bas” les sons les moins forts, ce qui a pour effet de faire ressortir facilement la voix dans le mix par rapport aux autres instruments.
Pour plus d’informations, je vous invite à consulter mon tutoriel sur la compression parallèle.
Etape 10 : Réverbe et Delay
Enfin, la dernière étape consiste bien souvent à positionner la voix lead dans un espace stéréo, en trois dimensions.
C’est-à-dire, ajouter de la réverbe sur votre piste de voix.
Par défaut, je vous conseille plutôt de le faire en dernier pour éviter que l’effet ne vienne masquer certains défauts ou certains problèmes de votre mix.
Enfin, je dis la réverbe, mais il est également possible d’utiliser d’autres effets comme par exemple les delays.
Tout simplement, cela dépend des styles de musique et de la densité de l’effet que vous recherchez.
Réverbe
Pour rendre la voix moins sèche, ajouter un plugin de réverbe est souvent la solution la plus simple.
En effet, cet effet permet instantanément de rendre une voix plus intéressante en lui donnant une dimension stéréo.
La contrepartie, c’est que plus vous mettrez de réverbe sur une voix, plus celle-ci va sembler éloignée :
La durée de la réverbe et son volume relatif par rapport à la piste de voix vont donc être deux paramètres critiques qu’il vous faudra absolument maîtriser :
- une réverbe trop longue va noyer le signal de base et les paroles seront moins intelligibles ;
- une réverbe trop forte donnera une sensation d’éloignement de la source sonore.
Du coup, pour certains genres musicaux modernes qui nécessitent une voix très frontale dans le mix, il vous faudra peut-être faire l’impasse sur la réverbe.
Ensuite, le type de réverbe va également influer sur son efficacité au sein du mix.
Personnellement, j’ai une petite préférence pour les réverbes à plaques (notamment Abbey Road Reverb Plates de Waves : -10% avec ce lien et le code qui s’affiche) ainsi que pour certaines réverbes algorithmiques (comme celles de ValhallaDSP).
Mais vous êtes libre, bien sûr, d’expérimenter avec toutes sorties de plugins.
Delay
Lorsqu’une réverbe ne convient pas pour donner de la dimension à une piste de voix, il peut être intéressant d’utiliser un effet de delay (ou écho en français, c’est la même chose).
Cela peut paraître surprenant, car le delay est souvent perçu un peu comme un effet spécial, mais c’est pourtant un effet couramment utilisé lors du mixage des voix.
Plus précisément, de nombreux ingénieurs utilisent une technique que l’on appelle slapback delay — très simple mais extrêmement efficace pour donner de la profondeur à une voix.

Concrètement, celle-ci consiste en l’utilisation d’un plugin de delay réglé de la façon suivante :
- un temps d’écho extrêmement court (50-100 ms en moyenne) ;
- une seule répétition (donc un réglage de feedback à 0%) ;
- mono uniquement (la répétition du signal dans le canal de gauche est identique à celle du canal de droite).
Bien entendu, égaliser l’effet d’écho est nécessaire pour éviter qu’il ne prenne trop le dessus par rapport à la piste de base.
Rendez-vous sur cet article pour un peu plus d’infos sur le sujet.
Bravo, vous savez maintenant mixer une voix !
Tout d’abord, félicitations d’être arrivé(e) à la fin de ce long article ! 🙂
Vous connaissez désormais les étapes pour réussir le mixage d’une voix lead, peu importe le style de musique ou l’enregistrement (même si la qualité de votre mix dépendra bien sûr de la qualité de la prise de son).
Maintenant, la dernière étape, c’est tout simplement la mise en pratique : reprenez un ancien mix, retirez tous les effets de la piste de voix et recommencez à la mixer en suivant les étapes de cet article.
Puis faites la même chose sur votre prochain morceau.
Rapidement, vous allez remarquer que vos pistes de chant seront plus percutantes et qu’elles prendront plus leur place dans le mix.
Sur ce, à bientôt pour d’autres articles sur le mixage audio 🙂
Commentaires (94)
Laisser un commentaire
Salut à tous, franchement top cet article ! J’ai une petite expérience dans le mixage de voix qui s’est peaufinée avec le temps à cause d’erreurs commises. Aujourd’hui j’arrive à un résultat plutôt pas mal mais pas assez professionnel. Cet article va m’aider dans l’approche de mes réglages et me déshabituer du preset : EQ – Comp – De-esser basique. En mode Nivunikonu !
Merci beaucoup !! 🙂
Top l’article merci beaucoup Adrien !
Différemment du comping, je me demandais si moyenner plusieurs voix était intéressant et quelles étaient les techniques pour faire une bonne moyenne (ne pas avoir un effet robotique, des problèmes de phase ou autre) quand on superpose 2 voix ou plus ? Je parle plutôt de voix avec la même tonalité (pas une aigue et une grave en arrière). Y-a-t-il un intérêt ? Est-ce que ça se fait ? Si oui comment bien le faire ?
Merci beaucoup ! 🙂
Guibs
Tu peux avoir plusieurs pistes de voix, c’est souvent fait pour les chœurs notamment. Pour une voix lead, je suis pas sûr que ça soit vraiment une bonne idée. Enfin ça ne sonnera pas comme un comping, ça fera plutôt un effet chorus
Merci Adrien, Je me sent prêt grâce à ton article à mixer une voix. Je ais suivre cet article étape par étape.
Merci beaucoup !
Peter Pawn
Avec plaisir 🙂 !
Très bon article bien expliqué. Ça change des tuto ou on nous balance des réglages tout prêt qui au final ne servent à rien car chaque mix est complètement différent. Pour moi ce qui à fait la différence c’est quand j’ai commencé à faire EQ soustractif, compression, et EQ additif alors qu’avant je compressait d’abord et ajoutait un seul EQ ensuite. Depuis mes mix, que ce sois voix ou instrus, sonnent beaucoup mieux.
Merci pour ces articles de qualité. Musicalement.
Super, merci beaucoup pour ce retour très positif 🙂 !
Merci Adrien! Du coup je vais suivre tes explications pour améliorer le morceau que tu m’as masterisé.
Tout est toujours clair et efficace! Bravo !
Merci à toi 🙂 !