Das Mischen von Stimmen ist wahrscheinlich einer der kompliziertesten Aspekte des Audio-Mixings.
Einfach weil wir viel sensibler auf den Realismus einer Stimme in einer Aufnahme reagieren als auf den Realismus einer E-Gitarre oder eines Schlagzeugs.

Als ich anfing, meine eigenen Stücke zu mischen, hatte ich große Schwierigkeiten zu verstehen, was ich tun sollte und warum. Welches Processing hinzuzufügen, welche Einstellungen für diesen oder jenen Effekt anzuwenden.
Ich fügte Plugins hinzu, indem ich den Ratschlägen folgte, die ich gelesen oder gehört hatte, aber ohne den Einfluss zu verstehen, den dies auf den Mix hatte.
Das alles schien mir ziemlich mysteriös, tatsächlich …
… weil ich die wesentlichen Schritte zum Mischen einer Stimme nicht beherrschte.
Denn tatsächlich, auch wenn es keine Regeln gibt, um ein erfolgreiches Stimm-Mixing zu erreichen, gibt es dennoch eine Reihe von Standard-Schritten, die fast unvermeidlich sind. Und das, egal ob Sie Ihr Mixing in FL Studio, Cubase oder jeder anderen DAW durchführen.
Hier also, durch diesen Artikel, ein detaillierter und “Schritt-für-Schritt” Überblick darüber, was zu tun ist, wenn man beginnt, eine Lead-Vocal-Spur zu mischen.
Schritt 1: Definieren Sie ein Ziel
Der größte Fehler, den Sie beim Vocal-Mixing machen könnten, ist, sich ohne ein definiertes Ziel-Sound auf den Weg zu machen.
Ich würde sogar sagen, es ist, Ratschläge anzuwenden, die Sie hier und da, im Internet oder anderswo gehört haben, ohne über ihre Relevanz in Ihrem Mix nachgedacht zu haben.
“Komprimieren Sie mit einem Verhältnis von 6:1 und einer Attack-Zeit von 15 ms.”
“Fügen Sie einen Equalizer hinzu und schneiden Sie um -5 dB mit einem Glockenfilter bei 1200 Hz”
… all diese Ratschläge sind mit Vorsicht zu genießen, denn:
- sie sind nur auf das Stück / das Mixing der Person anwendbar, die sie gibt, da sie zu 100 % vom aufgenommenen Klangsignal abhängen;
- sie werden notwendigerweise je nach Musikgenre variieren: Man wird eine Stimme für Jazz, Pop oder Hard Rock ganz anders komprimieren.
Das ist der Grund, warum Sie auf Projet Home Studio fast keine Zahlen, keine “Einstellungen für ein gutes Stimm-Mixing” finden werden, sondern nur Richtlinien.
Aber wie macht man das nun?
Nun, das erste, was man tun sollte, bevor man eine Gesangsspur mischt, ist, sich die Frage nach dem gewünschten Klang zu stellen.
Suchen Sie einen aggressiven, frontalen Klang?
Oder eher etwas Sanftes und Luftiges, mit vielen dynamischen Variationen?
Würde Ihr Stück besser mit einer sehr trockenen Stimme oder im Gegenteil mit viel Hall harmonieren?
Nehmen Sie sich die Zeit, über solche Fragen nachzudenken, um Ihren Ziel-Stimmenklang zu definieren — falls nötig, finden Sie ein Referenzstück, das dem ähnelt, was Sie erreichen möchten.
Das wird Ihnen helfen, Ihre Stimme mit einem klaren Ziel zu mischen, das zu Ihrem Stück passt.
Schritt 2: Bereiten Sie Ihre Gesangsspur vor dem Mixing vor
Im Allgemeinen, wenn wir an das Mischen von Lead-Vocals denken, denken wir sofort an die Plugins, die wir hinzufügen werden.
Das ist normal: Es ist der unterhaltsamste Teil des Mixings.
Dennoch ist es wirklich wichtig, die Gesangsspur richtig vorzubereiten, bevor man irgendwelche Effekte hinzufügt.
Wenn wir davon ausgehen, dass die Aufnahme von guter Qualität ist, wird sich diese “Vorbereitung” in zwei großen Aktionen niederschlagen: Comping und Editing.
Das Comping
Im Allgemeinen werden Sie für dieselbe Gesangslinie mehrere Takes machen.
In den 60er Jahren wurden viele Stücke in “One Take” (einer Aufnahme) gemacht, insbesondere weil die Aufnahmen auf Magnetbändern gemacht wurden.
Heute ermöglichen die Technologie und die Speicherkapazitäten unserer PCs, leicht drei oder vier Takes für dasselbe Stück zu machen.
Die unmittelbare Konsequenz: Für eine gegebene Gesangslinie können Sie die besten Passagen auswählen und kombinieren.
Wenn zum Beispiel die 1ste Phrase auf Take A besser ist als auf Take B, behalten Sie Take A. Und so weiter für jede Phrase, jeden Vers … bis Sie eine vollständige und perfekte Spur erhalten!
Vielleicht haben Sie das Gefühl, dass es ein bisschen schummeln ist. Ich versichere Ihnen: Diese Technik, die man comping nennt, wird von den meisten professionellen Studios verwendet.
Außer im Fall des Hits My Heart Will Go On, aber nicht jeder ist Céline Dion! 😉
Nehmen Sie sich also die Zeit, mehrere Takes zu machen und diese zu einer einzigen Spur zusammenzustellen.
Tipps: Um Ihnen zu helfen, die Teile Ihres Stücks auszuwählen, können Sie ein comp sheet wie dieses verwenden, indem Sie die besten Passagen notieren:

Die Bearbeitung
Selbst bei sehr guten Aufnahmen gibt es immer Dinge, die man nicht behalten möchte, wie Atemgeräusche oder das Geräusch des Kopfhörers im Mikrofon während ruhiger Passagen.
Im Kontext eines Home Studios kann es je nach den Bedingungen, unter denen Sie aufnehmen, noch viel schlimmer sein:
- Hintergrundgeräusche vom Computer;
- Hintergrundgeräusche von der Klimaanlage;
- ein Vogel oder ein Auto draußen;
- …
Wenn der Sänger oder die Sängerin singt, wird diese Art von Geräusch normalerweise überdeckt, sodass es nicht zu viele Probleme verursacht (aber schalten Sie Ihre Klimaanlage trotzdem aus, wenn Sie aufnehmen…).
Bei ruhigen Passagen zwischen den Sätzen oder Strophen müssen diese Anomalien jedoch unbedingt entfernt werden, da sie beim Mischen durch die Kompression noch stärker hervortreten könnten.

Dazu müssen Sie einfach:
- die Passagen, die Sie nicht behalten möchten, mit dem entsprechenden Werkzeug Ihrer DAW ausschneiden;
- dann schnelle Überblendungen am Anfang und Ende jeder Audio-Spur hinzufügen, um digitale Klicks zu vermeiden.
Am Ende erhalten Sie also eine so saubere Sprachspur wie möglich, die einfacher zu mischen ist.
Schritt 3: Gain Staging
Sobald Ihre Spur korrekt bearbeitet wurde, ist es normalerweise der richtige Zeitpunkt, um das Niveau der Sätze oder Silben anzupassen.
Mit anderen Worten, um eine Art Gain Staging zu machen.
Dieser Schritt ist super wichtig, da er wirklich den Unterschied zwischen einem Amateur-Mix und einem Profi-Mix ausmacht.
Zumindest was das Mischen der Lead-Vocals betrifft.
Stellen Sie sich vor, Sie haben eine Gesangsspur mit sanften und lauten Passagen:

Wenn Sie die Spur so lassen und versuchen, sie zu komprimieren, werden Sie folgendes Problem haben:

- Wenn Sie mit einem hohen Schwellenwert komprimieren, werden nur die lauten Passagen betroffen sein;
- aber wenn Sie den Schwellenwert absenken, um die leisen Passagen zu berücksichtigen, werden die lauten Passagen durch die Kompression völlig erdrückt, da sie weit über dem Schwellenwert liegen.
Wenn Sie jedoch das Niveau der Spur Satz für Satz, Vers für Vers und sogar Silbe für Silbe anpassen, werden Sie Probleme beim Hinzufügen von Effekten vermeiden und können sicherstellen, dass jedes Wort im Mix verständlich ist.
Es ist nicht immer notwendig, bis zur Silbe zu gehen, aber stellen Sie dennoch sicher, dass die Sätze im Durchschnitt auf dem richtigen Niveau sind.
Zu diesem Zweck können Sie entweder ein einfaches Gain-Plugin mit einer Automationskurve verwenden oder ein automatisches Gain-Plugin wie den Vocal Rider von Waves verwenden.
Es ist zu beachten, dass letzteres automatisch eine Automationskurve generieren kann, die Sie bei Bedarf manuell bearbeiten können, um etwas präziser zu sein.
Schritt 4: Subtraktive Equalisierung
In den meisten Fällen ist das erste, was Sie beim Mischen einer Lead-Stimme tun müssen, sie mit Equalization zu reinigen.
Oder genauer gesagt, die Frequenzen zu korrigieren, die Ihnen unangenehm erscheinen.
Typischerweise finden wir oft Dröhnen in den tiefen Frequenzen, unterhalb von 50-100 Hz, die eher Hintergrundgeräusche (elektronisch, von außen…) als die Stimme selbst entsprechen.
All dies können Sie leicht mit Hochpassfiltern (oder Low-Shelf-Filtern) entfernen oder abschwächen.
Danach müssen Sie die anderen Frequenzprobleme korrigieren, die Sie hören.
Diese können mit verschiedenen mehr oder weniger beherrschbaren Ursachen verbunden sein, wie:
- die Akustik des Raumes, in dem Sie aufnehmen (ohne akustische Behandlung können Sie beispielsweise unter dem Effekt von modalen Resonanzen leiden);
- Frequenzen, die für das Ohr etwas hart sind, die mit der Konstruktion des Mikrofons und/oder der Qualität des Vorverstärkers verbunden sind;
- Frequenzen, die etwas störend sind und bei einem Mikrofon mehr hervortreten als bei einem anderen (das hängt von den Sängern/Sängerinnen ab);
- die Qualität der Darbietung des Sängers / der Sängerin.

Um diese Probleme zu korrigieren, ist es am einfachsten, die übliche Technik der klassischen Equalisierung zu verwenden:
- Identifizieren Sie das Problem oder das Element, das Sie korrigieren möchten
- Fügen Sie einen EQ-Bell-Filter hinzu mit
- einem relativ hohen Q-Faktor (4 bis 10)
- einer hohen Verstärkung (+10 dB zum Beispiel)
- Durchsuchen Sie langsam das Frequenzspektrum mit diesem Filter, bis Sie das Problem deutlich hervortreten hören (in Form von Resonanz, zum Beispiel)
- Schwächen Sie das Signal (anstatt der +10dB) auf dem Frequenzband, auf dem Sie sich befinden, indem Sie bei Bedarf den Q-Faktor anpassen
Ich betone besonders den ersten Punkt: nehmen Sie sich die Zeit, zuerst Ihre Spur anzuhören, um die Elemente zu identifizieren, die Sie stören. Tatsächlich ist das Mischen von Stimmen zwar etwas Präzises, es ist jedoch unnötig, winzige Probleme zu korrigieren, die im Gesamtbild nicht hörbar sind, aber durch den Filter bei +10 dB hervorgehoben würden…
Sobald dieser Schritt abgeschlossen ist, könnte Ihr EQ so aussehen (aber vielleicht auch ganz anders, da es immer vom Quellsignal abhängt):

Beachten Sie, dass wir hier von einer Equalisierung für eine Lead-Stimme sprechen. Wenn Sie beispielsweise Chöre mischen, wird die Equalisierung wahrscheinlich sehr unterschiedlich sein.
Schritt 5: De-Esser
Einige Buchstaben oder Silben neigen dazu, aggressiv in den Höhen hervorzutreten, wenn sie von einem Mikrofon aufgenommen werden.
Typischerweise handelt es sich um Laute wie den Konsonanten “S”, aber auch um “F”, “T” oder “CH”.
Dies ist ein Audio-Phänomen, das man allgemein als Sibilanz bezeichnet und das je nach Mikrofon und Form des Mundes des Sängers / der Sängerin mehr oder weniger stark auftreten kann.
Die Tatsache, dass diese Laute hervortreten, kann eine Reihe unangenehmer Folgen für Ihr Mixing haben: Einerseits wird es schnell ärgerlich für den Zuhörer, andererseits wird es auch die Nachhall-Effekte beeinträchtigen, die Sie später hinzufügen werden, die sehr empfindlich auf diese Laute reagieren.
Hören Sie sich beispielsweise den Effekt der “S” auf die Textur des Nachhalls in diesem Beispiel an:
Es ist daher wichtig, dieses Sibilanz-Phänomen so gut wie möglich zu kontrollieren.
Sicherlich gibt es Aufnahmetipps für die Stimme, die helfen, das Problem zu minimieren, aber oft müssen Sie das Problem im Mixing angehen.
Leider ist es unmöglich, einen einfachen Equalizer zu verwenden, um das Signal bei 4 oder 5 kHz abzuschneiden: Wenn Sie dauerhaft abschneiden, wird dies die gesamte Spur beeinträchtigen und die Stimme wird seltsam klingen.
Die Lösung besteht also darin, einen sogenannten De-Esser zu verwenden, wie den Pro-G von Fabfilter (oder eine dieser kostenlosen Alternativen):
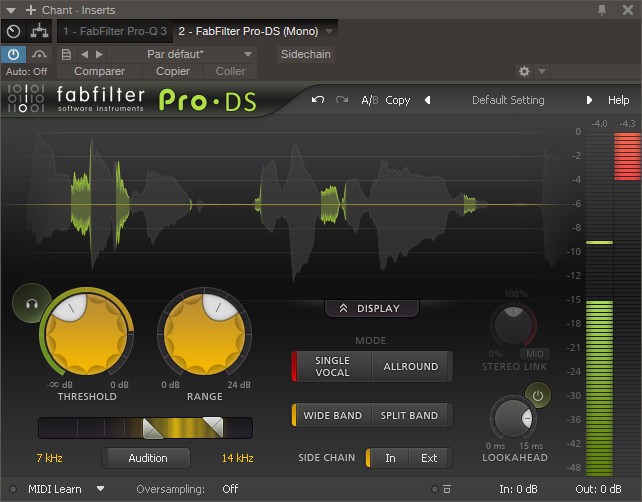
Durch einen Multiband-Algorithmus ermöglicht dieser Effekt, die Sibilanz zu kontrollieren, indem nur bestimmte Frequenzen abgeschwächt werden, wenn “S”-Laute erkannt werden.
Somit werden Frequenzen, die nicht betroffen sind, nicht beeinflusst.
Achten Sie jedoch darauf, das Plugin nicht zu extrem einzustellen, um das Signal nicht zu verschlechtern: Einige Dezibel an Gain Reduction (GR) sollten in den meisten Fällen ausreichen.
Schritt 6: Kompression, unvermeidlich für das Mixing von Stimmen
Da das Signal nun gereinigt ist, können Sie mit der Kompression der Sprachspur beginnen.
Manchmal benötigen Sie keine Kompression. Vielleicht, weil das Musikgenre es nicht zulässt, oder weil bereits eine analoge Kompression während des Trackings stattgefunden hat.
Das gesagt, 99% der Zeit sind Sprach- oder Gesangsaufnahmen ziemlich dynamisch: Einige Phrasen, einige Silben werden hervorgehoben, während andere weniger betont werden.
Folge: Es ist unmöglich, alle Wörter im Mixing verständlich herauszuarbeiten. Mit anderen Worten, wenn Sie versuchen, den Lautstärkeregler Ihrer Sprachspur anzupassen, werden Sie keinen passenden Wert finden: Manchmal ist die Spur zu laut und Sie möchten den Regler senken, und zu anderen Zeiten sind die Worte im Mix verloren und Sie möchten den Regler erhöhen.
Das ist ein Zeichen dafür, dass Ihre Spur Kompression benötigt, um ihren Dynamikbereich zu reduzieren.
Fügen Sie also den Kompressor Ihrer Wahl auf die Spur hinzu (zu Beginn kann der standardmäßig in Ihrer DAW enthaltene eine gute Ausgangsbasis sein) und stellen Sie ihn ein, um Ihre Spur zu nivellieren:

Die Menge an Kompression, die Sie anwenden werden, die der Gain Reduction (GR) entspricht, hängt vom Musikstil ab: Bei akustischer Musik oder Jazz werden Sie wahrscheinlich einen minimalen Effekt anstreben, während Sie bei Rap oder Heavy Metal eine viel frontalere, durchdringendere Stimme benötigen.
Das gesagt, das Ziel ist dennoch, dass der Kompressionseffekt so wenig hörbar wie möglich ist, da Kompression Audioartefakte erzeugen kann (typischerweise einen Pump-Effekt).
Wenn ein einzelner Kompressor nicht ausreicht, um das Niveau der Sprachspur zu homogenisieren, zögern Sie nicht, zwei hintereinander zu verwenden, um verschiedene Aspekte der Spur zu bearbeiten (sehen Sie sich meinen Leitfaden zur Sprachkompression für weitere Erklärungen an).
Schritt 7: Additive Equalisation
Nach der Kompression ist es in der Regel der richtige Zeitpunkt, um ein EQ hinzuzufügen, das additiv arbeitet, das heißt mit positiven Gain-Einstellungen.
Die Idee ist, dass Sie jetzt, da Sie die Probleme des Signals durch subtraktive Equalisation (oder den eventuell verwendeten De-Esser) entfernt haben und die Dynamik durch die Kompression korrekt kontrolliert wird, die Frequenzantwort verfeinern, indem Sie das verstärken, was Sie mehr hören möchten oder brauchen.
Mit anderen Worten, Sie werden das Mixing Ihrer Sprachspur verbessern, indem Sie Ihren Sound gestalten.
Es liegt an Ihnen, welche Frequenzen Sie anheben und wie viel Gain Sie anwenden möchten, aber es ist beispielsweise üblich, die Bässe etwas anzuheben, um der Stimme mehr Körper zu verleihen, oder die Höhen anzuheben, um der Stimme Luft zu geben und ihr zu helfen, sich im Mix abzuheben.
Hier ist ein Beispiel für ein Stück, bei dem die Höhen extrem angehoben sind (nicht sehr angenehm, aber gut…):
Das bringt mich zu einem wichtigen Punkt: Natürlich mag ich es nicht, sehr präzise Regeln zu geben, aber wenn Sie feststellen, dass Ihre Equalisierung über +5 oder +6 dB hinausgeht, stellen Sie sich die Frage “Macht das, was ich tue, Sinn?”.
Während das bei einem Schlagzeug leicht nachvollziehbar sein kann, kann das Verfälschen einer Gesangsspur sehr schnell geschehen — deshalb ist es notwendig, vorsichtig zu sein.
Beispiel: Anstatt die Höhen um +15 dB anzuheben, könnte es sein, dass der Mix insgesamt in den Höhen zu laut ist? In diesem Fall reduzieren Sie besser die Höhen auf anderen Spuren, anstatt die Gesangsspur zu verfälschen… 😉
Schritt 8: Saturation (optional)
Es ist völlig optional, aber manchmal kann es interessant sein, harmonische Saturation hinzuzufügen.
Es kann sich um eine maximale Saturation handeln, um einen speziellen Effekt wie Verzerrung zu erzeugen, aber standardmäßig empfehle ich Ihnen, eher in subtileren Saturationseinstellungen zu bleiben.
Die Idee ist, den harmonischen Inhalt des Signals zu verstärken, um den Klang etwas wärmer, interessanter und bemerkenswerter im Mix zu machen.
Beachten Sie, dass diese Technik nicht spezifisch für das Mischen von Stimmen ist: Sie kann auf alle Arten von Instrumenten angewendet werden.

Natürlich, wenn die Aufnahme bereits mit einem gefärbten Vorverstärker (z.B. Neve) durchgeführt wurde, wird das Hinzufügen von Saturation wahrscheinlich nicht viel bringen — oder sogar die Qualität des Mixes beeinträchtigen.
Wenn der verwendete Vorverstärker jedoch neutral ist (was bei den meisten in Soundkarten integrierten Vorverstärkern der Fall ist) oder dazu neigt, einen eher flachen Klang zu erzeugen, dann lohnt es sich wahrscheinlich, ein wenig kosmetische Saturation hinzuzufügen, zum Beispiel mit Plugins, die Bandmaschinen simulieren.
Einige Empfehlungen für Plugins:
- Kazrog True Iron ;
- Waves J37 (-10% mit diesem Link und dem angezeigten Code) ;
- Soundtoys Radiator ;
- oder zum Beispiel eines von diesen kostenlosen Saturation-Plugins.
Schritt 9: Parallele Kompression (optional)
Natürlich können alle Arten von Behandlungen auf Stimmen angewendet werden.
Das Ziel dieses Artikels ist es daher nicht, die Vielzahl der bestehenden Möglichkeiten aufzulisten — sonst wären Sie einfach inmitten all dieser Informationen verloren (zumal es bereits viele auf dieser Seite gibt 🙂 ).
Eine Technik, die sowohl sehr praktisch als auch häufig verwendet wird, ist die sogenannte “parallele Kompression” oder auch “New York Compression”.
Diese Methode besteht darin, eine identische Spur zur Basisgesangsspur stark zu komprimieren und sie dann subtil mit dem Originalsignal zu remixen.
Das ermöglicht es, die Spitzen und einen Teil der Dynamik des Signals zu erhalten, während die leiseren Töne “von unten” unterstützt werden, was dazu führt, dass die Stimme im Mix im Vergleich zu den anderen Instrumenten leicht hervorsticht.
Für weitere Informationen lade ich Sie ein, mein Tutorial zur parallelen Kompression zu konsultieren.
Schritt 10: Reverb und Delay
Schließlich besteht der letzte Schritt oft darin, die Leadstimme in einem Stereo-Raum, in drei Dimensionen, zu positionieren.
Das heißt, Reverb auf Ihrer Gesangsspur hinzuzufügen.
Standardmäßig empfehle ich, dies eher als letzten Schritt zu tun, um zu vermeiden, dass der Effekt einige Mängel oder Probleme Ihres Mixes überdeckt.
Schließlich sage ich Reverb, aber es ist auch möglich, andere Effekte wie zum Beispiel Delays zu verwenden.
Ganz einfach, es hängt von den Musikstilen und der Dichte des Effekts ab, den Sie suchen.
Reverb
Um die Stimme weniger trocken zu machen, fügt man oft ein Reverb-Plugin hinzu, was die einfachste Lösung ist.
Tatsächlich ermöglicht dieser Effekt sofort, eine Stimme interessanter zu gestalten, indem er ihr eine Stereo-Dimension verleiht.
Der Nachteil ist, dass je mehr Reverb Sie auf eine Stimme anwenden, desto weiter wird sie erscheinen:
Die Dauer des Reverbs und sein relatives Volumen im Vergleich zur Stimme sind daher zwei kritische Parameter, die Sie unbedingt beherrschen müssen:
- Ein zu langes Reverb wird das ursprüngliche Signal überlagern und die Worte werden weniger verständlich;
- Ein zu starkes Reverb vermittelt ein Gefühl der Entfernung von der Klangquelle.
Daher müssen Sie möglicherweise auf Reverb verzichten, wenn es um bestimmte moderne Musikgenres geht, die eine sehr frontale Stimme im Mix erfordern.
Außerdem wird auch die Art des Reverbs seine Effektivität im Mix beeinflussen.
Persönlich habe ich eine kleine Vorliebe für Platten-Reverbs (insbesondere Abbey Road Reverb Plates von Waves: -10% mit diesem Link und dem angezeigten Code) sowie für einige algorithmische Reverbs (wie die von ValhallaDSP).
Aber Sie sind natürlich frei, mit allen Plugin-Ausgaben zu experimentieren.
Delay
Wenn ein Reverb nicht geeignet ist, um einer Stimme Dimension zu verleihen, kann es interessant sein, einen Delay-Effekt (oder Echo auf Französisch, das ist dasselbe) zu verwenden.
Das mag überraschend erscheinen, denn Delay wird oft als Spezialeffekt wahrgenommen, ist aber dennoch ein häufig verwendeter Effekt beim Mischen von Stimmen.
Genauer gesagt verwenden viele Ingenieure eine Technik, die man Slapback Delay nennt – sehr einfach, aber extrem effektiv, um einer Stimme Tiefe zu verleihen.

Konkret besteht dies darin, ein Delay-Plugin wie folgt einzustellen:
- eine extrem kurze Echozeit (im Durchschnitt 50-100 ms);
- eine einzige Wiederholung (also eine Feedback-Einstellung von 0%);
- nur Mono (die Wiederholung des Signals im linken Kanal ist identisch mit der im rechten Kanal).
Natürlich ist es notwendig, den Echo-Effekt zu equalizen, um zu vermeiden, dass er im Vergleich zur Basis-Spur zu dominant wird.
Besuchen Sie diesen Artikel für weitere Informationen zu diesem Thema.
Bravo, Sie wissen jetzt, wie man eine Stimme mischt!
Zunächst einmal herzlichen Glückwunsch, dass Sie am Ende dieses langen Artikels angekommen sind! 🙂
Sie kennen jetzt die Schritte, um das Mischen einer Lead-Stimme erfolgreich zu gestalten, egal welchen Musikstil oder welche Aufnahme (auch wenn die Qualität Ihres Mixes natürlich von der Qualität der Aufnahme abhängt).
Jetzt ist der letzte Schritt einfach die praktische Anwendung: Nehmen Sie einen alten Mix, entfernen Sie alle Effekte von der Stimme und beginnen Sie, sie gemäß den Schritten in diesem Artikel neu zu mischen.
Dann machen Sie dasselbe mit Ihrem nächsten Stück.
Schnell werden Sie merken, dass Ihre Gesangsspuren durchschlagender werden und mehr Platz im Mix einnehmen.
In diesem Sinne, bis bald für weitere Artikel über Audio-Mixing 🙂