Mixning av sång är förmodligen en av de mest komplicerade aspekterna av ljudmixning.
Det beror helt enkelt på att vi är mycket mer känsliga för realismen av en röst i en inspelning än för realismen av en elgitarr eller ett trumset.

När jag började mixa mina egna låtar hade jag mycket svårt att förstå vad jag skulle göra och varför. Vilken behandling skulle jag lägga till, vilken inställning skulle jag tillämpa på olika effekter.
Jag lade till plugins baserat på råd jag hade läst eller hört, men utan att förstå vilken påverkan det hade på mixen.
Allt detta verkade ganska mystiskt, faktiskt, …
… eftersom jag inte behärskade de grundläggande stegen för att mixa en röst.
För det finns faktiskt, även om det inte finns några regler för att lyckas med en sångmix, ett antal standardsteg som är nästan oundvikliga. Och detta oavsett om du gör din mixning på FL Studio, Cubase eller något annat DAW.
Här är alltså, genom denna artikel, en detaljerad och “steg-för-steg” översikt över vad man ska göra när man börjar mixa en leadsång.
Steg 1: Definiera ett mål
Det största misstaget du kan göra när det gäller sångmixning är att ge dig in utan att ha definierat ett mål för ljudet.
Jag skulle till och med säga att det är att gå och tillämpa råd som du har hört här och där, på internet eller inte, utan att ha tänkt på deras relevans i ditt mix.
“Komprimera med ett förhållande på 6:1 och en attack på 15 ms.”
“Lägg till en equalizer och sänk med -5 dB med ett klockfilter vid 1200 Hz”
… alla dessa råd bör tas med en nypa salt eftersom:
- de är endast tillämpliga på låten / mixen av den person som ger dem eftersom de beror till 100% på det inspelade ljudsignalen;
- de kommer nödvändigtvis att variera beroende på musikgenren: man komprimerar absolut inte en röst på samma sätt för jazz, pop eller hårdrock.
Det är anledningen till att du knappt kommer att hitta några siffror, inga “inställningar för att mixa rösten bra” på Projet Home Studio, utan bara riktlinjer.
Men hur gör man då?
Tja, det första du bör göra innan du mixar en sångspår är att ställa frågan om vilket ljud du önskar.
Söker du ett aggressivt, frontalt ljud?
Eller kanske något mjukt och luftigt, med mycket dynamiska variationer?
Skulle din låt passa bättre med en mycket torr röst eller tvärtom något med mycket reverb?
Ta dig tid att tänka på den här typen av frågor för att definiera ditt mål för sångljudet — om det behövs, hitta en referenslåt som liknar det du vill göra.
Detta kommer att hjälpa dig att mixa din röst med ett klart mål, som kommer att motsvara din låt.
Steg 2: Förbered din sångspår innan mixning
Generellt sett, när man tänker på mixning av leadsång, tänker man genast på de plugins som man kommer att lägga till.
Det är normalt: det är den roligaste delen av mixningen.
Men innan du börjar lägga till effekter av något slag är det verkligen viktigt att förbereda din sångspår ordentligt.
Om vi utgår från att inspelningen är av god kvalitet, kommer denna “förberedelse” att översättas till två stora åtgärder: kompning och redigering.
Kompning
Generellt sett, för en och samma sånglinje, kommer du att göra flera tagningar.
På 60-talet gjordes många låtar i “one take” (en tagning), särskilt eftersom inspelningar gjordes på magnetband.
Idag gör teknologin och lagringskapaciteten på våra datorer det enkelt att göra tre eller fyra tagningar för samma låt.
Omedelbar konsekvens: för en given sånglinje kan du välja de bästa partierna och kombinera dem.
Till exempel, om den 1a frasen är bättre på tagning A än på tagning B, kommer du att behålla tagning A. Och så vidare för varje fras, varje vers… tills du får en komplett och perfekt spår!
Kanske har du intrycket av att det är lite fusk. Jag kan lugna dig: denna teknik, som kallas comping, används av de flesta professionella studior.
Förutom i fallet med låten My Heart Will Go On, men alla är inte Céline Dion! 😉
Ta dig tid att göra flera tagningar och kompilera dem till en enda spår.
Tips: för att hjälpa dig att välja delarna av ditt stycke kan du använda ett comp sheet som detta genom att notera de bästa delarna:

Redigeringen
Även på mycket bra ljudtagningar, finns det alltid saker som man inte vill behålla, som andningsljud eller ljudet av hörlurarna i mikrofonen under tysta partier.
I en hemmastudio, beroende på förhållandena under inspelningen, kan det vara mycket värre:
- bakgrundsljud från datorn;
- bakgrundsljud från luftkonditioneringen;
- en fågel eller en bil utanför;
- …
När sångaren eller sångerskan sjunger, täcks denna typ av ljud vanligtvis över, så det är inte så stort problem (men stäng av din luftkonditionering när du spelar in…).
Men på de tysta partierna mellan fraser eller verser måste dessa anomalier absolut tas bort, annars riskerar de att bli ännu mer framträdande under mixningen på grund av kompression.

För att göra detta behöver du bara:
- klippa bort de partier du inte vill behålla med hjälp av det lämpliga verktyget i din DAW;
- och sedan lägga till snabba övergångar i början och slutet av varje ljudstam för att undvika att digitala klick uppstår.
Slutligen kommer du att få en så ren röstspår som möjligt, vilket kommer att vara lättare att mixa.
Steg 3: Gain staging
När ditt spår har redigerats korrekt är det vanligtvis rätt tid att justera nivån på fraser eller stavelser.
Med andra ord, för att göra en slags gain staging.
Detta steg är superviktigt eftersom det verkligen kommer att göra skillnad mellan en amatörmix och en proffsmix.
Åtminstone när det gäller mixning av leadsång.
Låt oss föreställa oss att du har en sångspår med mjuka och starka partier:

Om du lämnar spåret så här och försöker komprimera det, kommer du att stöta på följande problem:

- om du komprimerar med en hög tröskel kommer endast de starka partierna att påverkas;
- men om du sänker tröskeln för att ta hänsyn till de svaga partierna, kommer de starka partierna att bli helt krossade av kompressionen eftersom de kommer att vara långt över tröskeln.
Å andra sidan, genom att justera nivåerna fras för fras, vers för vers, till och med stavelse för stavelse, kommer du att undvika problem när du lägger till effekter och du kan säkerställa att varje ord är begripligt i mixen.
Det är inte alltid nödvändigt att gå ner till stavelse, men se till att fraserna i genomsnitt ligger på rätt nivå.
För detta kan du antingen använda ett enkelt gain-plugin med en automation-kurva, eller använda ett automatiskt gain-plugin som Vocal Rider från Waves.
Det är värt att notera att det senare kan generera en automation-kurva automatiskt, som du kan redigera manuellt om det behövs för att bli lite mer exakt.
Steg 4: Subtraktiv equalization
Det mesta av tiden är det första du behöver göra när du mixar en lead-röst, att rengöra den med hjälp av equalization.
Eller mer specifikt, att korrigera frekvenser som inte låter behagliga.
Typiskt sett hittar man ofta buller i baserna, under 50-100 Hz, som mer motsvarar bakgrundsljud (elektriska, utomhus…) än själva rösten.
Allt detta kan du enkelt ta bort eller dämpa med högpassfilter (eller low-shelf).
Därefter måste du korrigera de andra frekvensproblemen som du hör.
Dessa kan vara relaterade till alla slags orsaker som är mer eller mindre hanterbara, såsom:
- akustiken i rummet där du spelar in (utan akustisk behandling kan du till exempel drabbas av modala resonansfenomen);
- frekvenser som är lite hårda för örat relaterade till mikrofonens konstruktion och/eller kvaliteten på förförstärkaren;
- frekvenser som är lite besvärliga i rösten som framträder mer med en mikrofon än med en annan (det beror på sångarna);
- kvaliteten på sångarens prestation.

För att korrigera dessa problem är det enklast att använda den vanliga klassiska equalizationstekniken:
- Identifiera problemet eller elementet som du vill korrigera
- Lägg till ett EQ-filter med klockform med
- en relativt hög Q-faktor (4 till 10)
- en hög förstärkning (+10 dB till exempel)
- Gå långsamt igenom frekvensspektrumet med detta filter tills du hör problemet framträda starkt (i form av resonans, till exempel)
- Dämpa signalen (istället för +10dB) på den frekvensband där du befinner dig genom att justera Q-faktorn vid behov
Jag betonar särskilt den första punkten: ta dig tid att först lyssna på din spår för att identifiera de element som stör dig. Även om mixning av röster är något som kräver precision, är det onödigt att korrigera små problem som inte hörs i det stora hela, men som skulle framhävas på grund av filtret på +10 dB…
När detta steg är avslutat kan din EQ kanske se ut så här (men kanske något helt annat, eftersom det alltid beror på källsignalen):

Notera att vi pratar om en equalization för en lead-röst. Om du till exempel mixar körer, kommer equalizationen sannolikt att vara mycket annorlunda.
Steg 5: De-Esser
Vissa bokstäver eller stavelser tenderar att framträda aggressivt i diskanten när de spelas in med en mikrofon.
Typiskt handlar det om ljud som konsonanten “S” men också “F”, “T” eller “CH”.
Detta är ett ljudfenomen som vi allmänt kallar sibilance och som kan uppträda mer eller mindre starkt beroende på mikrofonen och sångarens munform.
Att dessa ljud framträder kan ha ett antal obehagliga konsekvenser för din mix: å ena sidan kan det snabbt bli irriterande för lyssnaren, men det kan också skada de reverb-effekter som du kommer att lägga till efteråt, som är mycket känsliga för dessa ljud.
Lyssna till exempel på effekten av “S” på reverb-texturen i detta exempel:
Det är därför viktigt att kontrollera detta sibilance-fenomen så mycket som möjligt.
Visst finns det röstinspelningstips som kan minimera problemet, men ofta måste du hantera det under mixningen.
Tyvärr är det omöjligt att använda en enkel equalizer för att skära bort signalen vid 4 eller 5 kHz: om du stänger av konstant kommer det att påverka hela spåret och rösten kommer att låta konstig.
Lösningen är därför att använda det som kallas en de-esser som Fabfilters Pro-G (eller någon av dessa gratisalternativ):
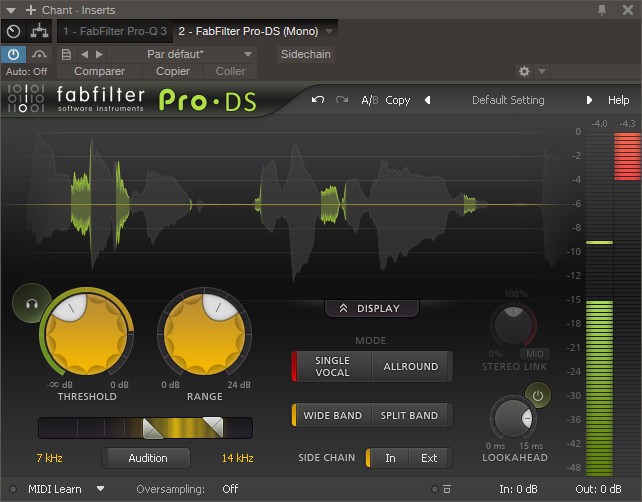
Genom en multibandsalgoritm kommer denna effekt att låta dig kontrollera sibilansen genom att dämpa endast vissa frekvenser när ljud som “S” upptäckts.
Så, utan att påverka frekvenser som inte är relaterade till problemet.
Var dock försiktig så att du inte ställer in pluginen för extremt, i risk för att försämra signalen: några decibel reduktion av gain (GR) bör räcka i de flesta fall.
Steg 6: Kompression, oundviklig för röstmixning
Nu när signalen är renad kan du gå vidare till kompression av röstspåret.
Ibland behöver du inte kompression. Kanske för att musikgenren inte tillåter det, eller för att det redan har skett en analog kompression under inspelningen.
Detta sagt, 99% av tiden visar sig röst- eller sånginspelningar vara ganska dynamiska: vissa fraser, vissa stavelser kommer att sticka ut medan andra kommer att vara mindre framträdande.
Konsekvens: omöjligt att få alla ord att framträda tydligt i mixen. Med andra ord, om du försöker justera volymfadern för ditt röstspår, kommer du inte att lyckas hitta en inställning som passar: ibland kommer spåret att vara för starkt och du kommer att vilja sänka fadern, och vid andra tillfällen kommer texterna att drunkna i mixen och du kommer att vilja höja fadern.
Detta är ett tecken på att ditt spår behöver kompression för att dess dynamiska omfång ska minskas.
Lägg därför till kompressorn av ditt val på spåret (för att börja med kan den som ingår som standard i din DAW vara en bra utgångspunkt) och justera den för att jämna ut ditt spår:

Mängden kompression du kommer att tillämpa, som motsvarar gainreduktion (Gain Reduction eller GR), kommer att bero på musikstilen: på akustisk musik eller jazz kommer du sannolikt att sikta på en minimal effekt, medan du på rap eller heavy metal kommer att behöva en mycket mer framträdande röst, mycket mer “rakt på”.
Detta sagt, målet är ändå att kompressionseffekten ska vara så lite hörbar som möjligt, eftersom kompression kan generera ljudartefakter (typiskt en pumpande effekt).
Om en enda kompressor inte räcker för att homogenisera nivån på röstspåret, tveka inte att använda två i följd för att behandla olika aspekter av spåret (kolla in min guide om röstkompression för mer förklaringar).
Steg 7: Additiv equalization
Efter kompressionen, är det vanligtvis en bra tid att lägga till en EQ som kommer att arbeta additivt, det vill säga med positiva gain-inställningar.
Idén är att nu när du har tagit bort problemen från signalen genom subtraktiv equalization (eller eventuell de-esser) och att dynamiken är korrekt kontrollerad av kompressionen, kommer du att fina till frekvensresponsen genom att förstärka det du vill eller behöver höra mer av.
Med andra ord, du kommer att förbättra mixen av ditt röstspår genom att forma ditt ljud.
Det är upp till dig att se vilka frekvenser som ska förstärkas och hur mycket gain som ska tillämpas, men till exempel är det vanligt att förstärka lite av baserna för att ge mer kropp åt rösten eller att lyfta diskanten för att ge luft och hjälpa rösten att sticka ut i mixen.
Här är ett exempel på en låt där diskanten är tryckt till det yttersta (inte särskilt trevligt, men okej…) :
Detta leder mig till en punkt av uppmärksamhet: visst, jag gillar inte att ge alltför exakta regler, men om du inser att din equalizer överstiger +5 eller +6 dB, ställ dig frågan “har det jag gör någon mening?”.
Så mycket som det kan förstås lätt på ett trumset, så kan att förvränga en sångspår vara mycket snabbt — det är därför det är nödvändigt att vara försiktig.
Exempel: istället för att boosta diskanten med +15 dB, kanske mixen som helhet är för stark i diskanten? I så fall, minska hellre diskanten på andra spår istället för att förvränga sångspåret… 😉
Steg 8: Saturation (valfritt)
Det är helt valfritt, men det kan ibland vara intressant att lägga till harmonisk saturation.
Det kan handla om att pressa saturation till max för att skapa en specialeffekt som distorsion, men som standard råder jag dig att hålla dig till mer subtila saturation-inställningar.
Idén är att förstärka det harmoniska innehållet i signalen för att göra ljudet lite varmare, lite mer intressant, lite mer framträdande i mixen.
Notera att denna teknik inte är specifik för sångmixning: den kan tillämpas på alla typer av instrument.

Naturligtvis, om inspelningen redan har gjorts med en färgad förförstärkare (typ Neve till exempel), kan det att lägga till saturation igen riskera att inte tillföra mycket — eller till och med skada kvaliteten på mixen.
Å andra sidan, om den använda förförstärkaren är neutral (vilket är fallet med de flesta förförstärkare som ingår i ljudkort) eller har en tendens att ge en ganska platt återgivning, då är det nog värt att lägga till lite kosmetisk saturation, med hjälp av plugins som simulerar bandspelare till exempel.
Några rekommendationer på plugins:
- Kazrog True Iron ;
- Waves J37 (-10% med denna länk och koden som visas) ;
- Soundtoys Radiator ;
- eller till exempel en av dessa gratis saturation-plugins.
Steg 9: Parallell kompression (valfritt)
Naturligtvis kan alla slags behandlingar tillämpas på sång.
Syftet med denna artikel är därför inte att lista de många möjliga alternativen — annars skulle du helt enkelt bli förvirrad mitt i all denna information (med tanke på att det redan finns mycket på denna sida 🙂 ).
Men en teknik som är både mycket praktisk och vanligt förekommande är den som kallas “parallell kompression” eller “New York Compression”.
Denna metod innebär att komprimera kraftigt ett spår som är identiskt med det grundläggande sångspåret och sedan blanda det subtilt med originalsignalen.
Detta gör att man kan behålla topparna och en del av signalens dynamik men samtidigt stödja “från botten” de svagare ljuden, vilket gör att sången lättare framträder i mixen i förhållande till andra instrument.
För mer information, rekommenderar jag att du kollar in min handledning om parallell kompression.
Steg 10: Reverb och Delay
Slutligen handlar det sista steget ofta om att placera leadsången i ett stereorum, i tre dimensioner.
Det vill säga, lägga till reverb på ditt sångspår.
Som standard rekommenderar jag att göra detta sist för att undvika att effekten döljer vissa brister eller problem i din mix.
Slutligen, jag nämner reverb, men det är också möjligt att använda andra effekter som till exempel delays.
Det beror helt enkelt på musikstilarna och den densitet av effekt som du söker.
Reverb
För att göra rösten mindre torr, lägga till en reverb-plugin är ofta den enklaste lösningen.
Faktum är att denna effekt omedelbart gör en röst mer intressant genom att ge den en stereodimension.
Nackdelen är att <strong ju mer reverb du lägger på en röst, desto mer kommer den att verka avlägsen:
Varaktigheten av reverben och dess relativa volym i förhållande till röstspåret kommer därför att vara två kritiska parametrar som du absolut måste behärska:
- en för lång reverb kommer att dränka bas-signalen och texterna blir mindre begripliga;
- en för stark reverb kommer att ge en känsla av avstånd från ljudkällan.
Därför, för vissa moderna musikgenrer som kräver en mycket frontal röst i mixen, kan det hända att du måste avstå från reverben.
Typen av reverb kommer också att påverka dess effektivitet i mixen.
Personligen har jag en liten preferens för plattreverb (särskilt Abbey Road Reverb Plates från Waves: -10% med denna länk och koden som visas) samt för vissa algoritmiska reverber (som de från ValhallaDSP).
Men du är självklart fri att experimentera med alla plugin-utgångar.
Delay
När en reverb inte passar för att ge dimension till ett röstspår kan det vara intressant att använda en delay-effekt (eller eko på franska, det är samma sak).
Det kan verka överraskande, eftersom delay ofta uppfattas som en specialeffekt, men det är faktiskt en effekt som vanligtvis används vid mixning av röster.
Mer specifikt använder många ingenjörer en teknik som kallas slapback delay — mycket enkel men extremt effektiv för att ge djup åt en röst.

Konkret handlar det om att använda en delay-plugin inställd på följande sätt:
- en extremt kort eko-tid (50-100 ms i genomsnitt);
- en enda upprepning (så en feedback-inställning på 0%);
- endast mono (upprepningen av signalen i vänster kanal är identisk med den i höger kanal).
Naturligtvis är det nödvändigt att justera eko-effekten för att undvika att den tar över för mycket i förhållande till bas-spåret.
Besök denna artikel för lite mer information om ämnet.
Bra jobbat, du vet nu hur man mixar en röst!
Först och främst, grattis till att du har kommit till slutet av denna långa artikel! 🙂
Du känner nu till stegen för att lyckas med mixningen av en lead-röst, oavsett musikstil eller inspelning (även om kvaliteten på din mix självklart kommer att bero på kvaliteten på inspelningen).
Nu är det sista steget helt enkelt att sätta det i praktik: ta en gammal mix, ta bort alla effekter från röstspåret och börja mixa det igen enligt stegen i denna artikel.
Gör sedan samma sak med din nästa låt.
Snart kommer du att märka att dina sångspår blir mer slagkraftiga och att de tar mer plats i mixen.
Med det sagt, vi ses snart för fler artiklar om ljudmixning 🙂