Miksowanie głosu jest prawdopodobnie jednym z najbardziej skomplikowanych aspektów miksowania audio.
Po prostu dlatego, że jesteśmy znacznie bardziej wrażliwi na realizm głosu w nagraniu niż na realizm gitary elektrycznej czy perkusji.

Kiedy zacząłem miksować swoje własne utwory, miałem wiele trudności ze zrozumieniem, co należy zrobić i dlaczego. Jakie przetwarzanie dodać, jakie ustawienie zastosować do danego efektu.
Dodawałem wtyczki, kierując się radami, które przeczytałem lub usłyszałem, ale bez zrozumienia wpływu, jaki miało to na miks.
Wszystko to wydawało mi się dość tajemnicze, w rzeczywistości…
… ponieważ nie opanowałem kluczowych kroków do miksowania głosu.
Bo rzeczywiście, chociaż nie ma reguł na udane miksowanie głosu, istnieje pewna liczba standardowych kroków, które są prawie nieuniknione. I to niezależnie od tego, czy miksujesz w FL Studio, Cubase czy jakimkolwiek innym DAW.
Oto zatem, w tym artykule, szczegółowy i “krok po kroku” przegląd tego, co należy zrobić, gdy zaczynasz miksować ścieżkę głosu wiodącego.
Krok 1: Zdefiniuj cel
Największym błędem, jaki możesz popełnić w kwestii miksowania wokalu, jest rozpoczęcie bez zdefiniowania celu dźwiękowego.
Powiedziałbym nawet, że to stosowanie rad, które usłyszałeś tu i tam, w Internecie lub nie, bez zastanowienia się nad ich adekwatnością w twoim miksie.
“Kompresuj z ratio 6:1 i atakiem 15 ms.”
“Dodaj equalizer i przytnij o -5 dB z filtrem dzwonowym przy 1200 Hz”
… wszystkie te porady należy traktować z przymrużeniem oka, ponieważ:
- mają zastosowanie tylko do utworu / miksu osoby, która je daje, ponieważ w 100% zależą od nagranego sygnału;
- koniecznie będą się różnić w zależności od gatunku muzycznego: nie skompresujemy w ten sam sposób głosu jazzowego, popowego czy hard rockowego.
To dlatego na Projekcie Home Studio prawie nie znajdziesz żadnych liczb, żadnych “ustawień do dobrego miksowania głosu”, ale tylko wytyczne.
Ale jak to zrobić?
Cóż, pierwszą rzeczą, którą należy zrobić przed miksowaniem ścieżki głosu, jest zadanie sobie pytania o dźwięk, który chcemy uzyskać.
Czy szukasz dźwięku agresywnego, frontalnego?
A może wręcz przeciwnie, czegoś delikatnego i eterycznego, z dużą ilością dynamicznych zmian?
Czy twój utwór lepiej zniesie bardzo suchy głos, czy wręcz przeciwnie, coś z dużą ilością pogłosu?
Poświęć czas na przemyślenie tego typu pytań, aby zdefiniować swój cel dźwiękowy — jeśli to konieczne, znajdź utwór referencyjny, który przypomina to, co chcesz osiągnąć.
Pomoże ci to miksować swój głos z jasnym celem, który będzie odpowiadał twojemu utworowi.
Krok 2: Przygotuj swoją ścieżkę głosu przed miksowaniem
Zazwyczaj, gdy myślimy o miksowaniu głosu wiodącego, od razu myślimy o wtyczkach, które dodamy.
To normalne: to najfajniejsza część miksowania.
Jednak zanim zaczniemy dodawać jakiekolwiek efekty, naprawdę ważne jest, aby odpowiednio przygotować swoją ścieżkę wokalną.
Jeśli zakładamy, że nagranie jest dobrej jakości, ta “przygotowanie” będzie się składać z dwóch głównych działań: kompingu i edycji.
Komping
Zazwyczaj, dla tej samej linii wokalnej, zrobisz kilka nagrań.
W latach 60. wiele utworów nagrywanych było w “jednym ujęciu”, głównie dlatego, że nagrania były robione na taśmach magnetycznych.
Dziś technologia i możliwości przechowywania w naszych komputerach pozwalają łatwo wykonać trzy lub cztery nagrania dla tego samego utworu.
Bezpośredni skutek: dla danej linii wokalnej będziesz mógł wybrać najlepsze fragmenty i je połączyć.
Na przykład, jeśli pierwsza fraza jest lepsza w nagraniu A niż w nagraniu B, zachowasz nagranie A. I tak dalej dla każdej frazy, każdego zwrotki… aż uzyskasz kompletną i idealną ścieżkę!
Może masz wrażenie, że to trochę oszustwo. Zapewniam cię: ta technika, nazywana comping, jest stosowana przez większość profesjonalnych studiów.
Oprócz w przypadku przeboju My Heart Will Go On, ale nie każdy jest Céline Dion! 😉
Poświęć więc czas na zrobienie kilku ujęć i skompiluj je w jedną ścieżkę.
Wskazówka: aby pomóc ci wybrać części twojego utworu, możesz użyć comp sheet takiej jak ta, notując najlepsze fragmenty:

Edycja
Nawet na bardzo dobrych nagraniach zawsze są rzeczy, których nie chcemy zachować, takie jak dźwięki oddechu czy szum słuchawek w mikrofonie podczas cichych fragmentów.
W kontekście domowego studia, w zależności od warunków, w jakich nagrywasz, może być znacznie gorzej:
- szum tła z komputera;
- szum tła z klimatyzacji;
- ptak lub samochód na zewnątrz;
- …
Kiedy wokalista śpiewa, ten rodzaj hałasu jest zazwyczaj przykryty, więc nie stanowi to zbyt dużego problemu (ale mimo to wyłącz klimatyzację podczas nagrywania…).
Natomiast w cichych fragmentach między zdaniami lub zwrotkami, należy bezwzględnie usunąć te anomalie, ryzykując, że będą one jeszcze bardziej słyszalne podczas miksowania z powodu kompresji.

Aby to zrobić, wystarczy:
- wyciąć fragmenty, których nie chcesz zachować, używając odpowiedniego narzędzia w swoim DAW;
- następnie dodać szybkie fade’y na początku i na końcu każdej ścieżki audio, aby uniknąć pojawiania się cyfrowych kliknięć.
Na koniec uzyskasz jak najczystsza ścieżkę wokalu, która będzie łatwiejsza do zmiksowania.
Krok 3: Gain staging
Gdy twoja ścieżka została poprawnie edytowana, to zazwyczaj dobry moment, aby dostosować poziom fraz lub sylab.
Innymi słowy, aby wykonać rodzaj gain staging.
Ten krok jest bardzo ważny, ponieważ naprawdę zrobi różnicę między amatorskim a profesjonalnym miksem.
Przynajmniej jeśli chodzi o miksowanie wokali głównych.
Wyobraź sobie, że masz ścieżkę wokalu z cichymi i głośnymi fragmentami:

Jeśli pozostawisz ścieżkę w takim stanie i spróbujesz ją skompresować, napotkasz następujący problem:

- jeśli skompresujesz z wysokim progiem, tylko głośne fragmenty będą miały wpływ;
- ale jeśli obniżysz próg, aby uwzględnić ciche fragmenty, głośne fragmenty zostaną całkowicie zgniecione przez kompresję, ponieważ będą znacznie powyżej progu.
Natomiast dostosowując poziom ścieżki zdanie po zdaniu, wers po wersie, a nawet sylaba po sylabie, unikniesz problemów podczas dodawania efektów i możesz upewnić się, że każde słowo jest zrozumiałe w miksie.
Nie zawsze jest konieczne schodzenie aż do sylaby, ale upewnij się, że średnio zdania są na odpowiednim poziomie.
Aby to zrobić, możesz użyć prostej wtyczki gain z krzywą automatyzacji lub skorzystać z wtyczki automatycznego ustawiania gain, takiej jak Vocal Rider od Waves.
Warto zauważyć, że ta ostatnia może automatycznie generować krzywą automatyzacji, którą w razie potrzeby możesz edytować ręcznie, aby być nieco bardziej precyzyjnym.
Krok 4: Ekwalizacja subtraktywna
Najczęściej pierwszą rzeczą, którą musisz zrobić podczas miksowania głosu prowadzącego, jest jego oczyszczenie za pomocą ekwalizacji.
Dokładniej mówiąc, poprawić częstotliwości, które nie brzmią przyjemnie.
Typowo często można spotkać dudnienia w niskich tonach, poniżej 50-100 Hz, które bardziej odpowiadają hałasom tła (elektrycznym, zewnętrznym…) niż samemu głosowi.
Wszystko to możesz łatwo usunąć lub osłabić za pomocą filtrów górnoprzepustowych (lub low-shelf).
Następnie będziesz musiał poprawić inne problemy z częstotliwościami, które słyszysz.
Mogą one być związane z różnymi przyczynami, które są mniej lub bardziej kontrolowalne, takimi jak:
- akustyka pomieszczenia, w którym nagrywasz (bez obróbki akustycznej możesz na przykład doświadczyć efektu rezonansów modalnych);
- częstotliwości, które są nieco trudne do zniesienia związane z budową mikrofonu i/lub jakością przedwzmacniacza;
- częstotliwości, które są nieco uciążliwe w głosie, które bardziej wybijają się z jednego mikrofonu niż z innego (to zależy od wokalistów);
- jakość występu wokalisty/wokalistki.

Aby poprawić te problemy, najprościej jest użyć tradycyjnej techniki ekwalizacji:
- Zidentyfikuj problem lub element, który chcesz poprawić
- Dodaj filtr EQ w kształcie dzwonu z
- relatywnie wysokim współczynnikiem Q (4 do 10)
- wysokim wzmocnieniem (+10 dB na przykład)
- Powoli przeszukuj spektrum częstotliwości z tym filtrem, aż usłyszysz, że problem staje się wyraźny (w postaci rezonansu, na przykład)
- Osłabiaj sygnał (zamiast +10dB) na poziomie pasma częstotliwości, na którym się znajdujesz, dostosowując w razie potrzeby współczynnik Q
Szczególnie podkreślam pierwszy punkt: poświęć czas na wysłuchanie swojej ścieżki, aby zidentyfikować elementy, które ci przeszkadzają. Rzeczywiście, miksowanie głosów, mimo że jest czymś precyzyjnym, nie ma sensu, jeśli chcesz poprawić drobne problemy, które nie są słyszalne w całości, ale które mogłyby być uwydatnione przez filtr na poziomie +10 dB…
Po zakończeniu tego kroku twoje EQ może wyglądać tak (ale może wyglądać zupełnie inaczej, ponieważ zawsze zależy to od sygnału źródłowego):

Zauważ, że mówimy o ekwalizacji dla głosu prowadzącego. Jeśli na przykład miksujesz chór, ekwaluacja będzie prawdopodobnie bardzo różna.
Krok 5: De-Esser
Niektóre litery lub sylaby mają tendencję do wybijania się w sposób agresywny w wysokich tonach po nagraniu przez mikrofon.
Typowo chodzi o dźwięki takie jak spółgłoska “S”, ale także “F”, “T” lub “CH”.
To zjawisko audio nazywamy ogólnie sibilancją i może występować w różnym stopniu w zależności od mikrofonu i kształtu ust wokalisty/wokalistki.
To, że te dźwięki się wybijają, może mieć szereg nieprzyjemnych konsekwencji dla twojego miksu: z jednej strony może to być szybko irytujące dla słuchacza, ale także zaszkodzi efektom pogłosu, które dodasz później, które są bardzo wrażliwe na te dźwięki.
Posłuchaj na przykład efektu “S” na teksturze pogłosu w tym przykładzie:
Dlatego ważne jest, aby maksymalnie kontrolować to zjawisko sibilancji.
Oczywiście, istnieją wskazówki dotyczące nagrywania głosu, które pozwalają zminimalizować problem, ale często będziesz musiał zająć się nim podczas miksowania.
Niestety, niemożliwe jest użycie prostego equalizera do odcięcia sygnału w zakresie 4 lub 5 kHz: jeśli będziesz ciągle odcinać, wpłynie to na całą ścieżkę, a głos będzie brzmiał dziwnie.
Rozwiązaniem jest więc użycie tzw. de-essera, takiego jak Pro-G od Fabfilter (lub jednej z tych darmowych alternatyw):
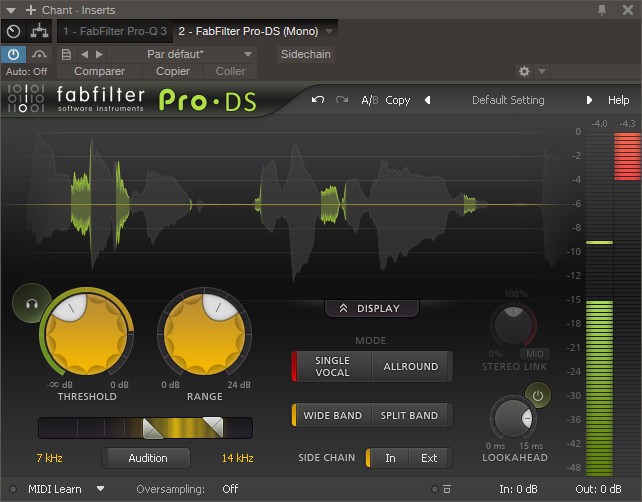
Dzięki algorytmowi multibandowemu, ten efekt pozwoli ci kontrolować sybilanty, tłumiąc tylko niektóre częstotliwości, gdy wykrywane są dźwięki typu “S”.
Tak więc, bez wpływania na częstotliwości, które nie są związane z problemem.
Uważaj jednak, aby nie ustawiać wtyczki w sposób zbyt ekstremalny, ryzykując pogorszenie sygnału: kilka decybeli redukcji wzmocnienia (GR) powinno wystarczyć w większości przypadków.
Krok 6: Kompresja, nieunikniona w miksowaniu głosów
Teraz, gdy sygnał jest już oczyszczony, możesz przejść do kompresji ścieżki głosu.
Czasami nie będziesz potrzebować kompresji. Może dlatego, że gatunek muzyczny na to nie pozwala, lub dlatego, że podczas nagrywania miała już miejsce kompresja analogowa.
Jednakże, 99% czasu nagrania głosu lub śpiewu okazują się być dość dynamiczne: niektóre frazy, niektóre sylaby będą się wyróżniać, podczas gdy inne będą mniej wyraźne.
Skutek: niemożliwe jest poprawne wydobycie wszystkich słów w sposób zrozumiały w miksie. Innymi słowy, jeśli spróbujesz dostosować suwak głośności swojej ścieżki głosu, nie będziesz w stanie znaleźć ustawienia, które by pasowało: w pewnych momentach ścieżka będzie zbyt głośna i będziesz chciał obniżyć suwak, a w innych momentach słowa będą zagłuszone w miksie i będziesz chciał podnieść suwak.
To znak, że twoja ścieżka potrzebuje kompresji, aby jej zakres dynamiczny został zmniejszony.
Dodaj więc kompresor według swojego wyboru do ścieżki (na początek, ten domyślnie zawarty w twoim DAW może być dobrym punktem wyjścia) i dostosuj go, aby wyrównać swoją ścieżkę:

Ilość kompresji, którą zastosujesz, odpowiadająca redukcji wzmocnienia (Gain Reduction lub GR), będzie zależała od stylu muzycznego: w muzyce akustycznej lub jazzie prawdopodobnie będziesz dążyć do minimalnego efektu, podczas gdy w rapie lub heavy metal będziesz potrzebować głosu znacznie bardziej wyrazistego, bardziej “wbijającego się”.
Jednakże, celem jest, aby efekt kompresji był jak najmniej słyszalny, ponieważ kompresja może generować artefakty audio (typowo, efekt pompowania).
Jeśli jeden kompresor nie wystarcza do ujednolicenia poziomu ścieżki głosu, nie wahaj się użyć dwóch z rzędu, aby zająć się różnymi aspektami ścieżki (zajrzyj do mojego przewodnika po kompresji głosu po więcej wyjaśnień).
Krok 7: Równoważenie dodające
Po kompresji, zazwyczaj jest to dobry moment, aby dodać EQ, który będzie działał w sposób dodający, to znaczy z pozytywnymi ustawieniami wzmocnienia.
Pomysł jest taki, że teraz, gdy usunąłeś problemy z sygnałem dzięki równoważeniu subtraktywnemu (lub ewentualnemu de-esserowi) i dynamika jest prawidłowo kontrolowana przez kompresję, będziesz udoskonalać odpowiedź częstotliwościową, wzmacniając to, co chcesz lub potrzebujesz usłyszeć bardziej.
Innymi słowy, poprawisz miks swojej ścieżki głosu poprzez rzeźbienie swojego dźwięku.
To od ciebie zależy, które częstotliwości wzmocnić i ile wzmocnienia zastosować, ale na przykład powszechne jest wzmacnianie nieco basów, aby nadać głosowi więcej ciała, lub podnoszenie wysokich tonów, aby nadać powietrze i pomóc głosowi wyróżnić się w miksie.
Oto przykład utworu, w którym wysokie tony są podbite do ekstremum (niezbyt przyjemne, ale cóż…) :
Co prowadzi mnie do punktu uwagi: oczywiście, nie lubię dawać zbyt precyzyjnych zasad, ale jeśli zauważysz, że twoje wyrównanie przekracza +5 lub +6 dB, zadaj sobie pytanie “czy to, co robię, ma sens?”.
Na perkusji może to być łatwe do zrozumienia, ale zniekształcenie ścieżki wokalnej może być bardzo szybkie — dlatego konieczne jest zachowanie ostrożności.
Przykład: zamiast podnosić wysokie tony o +15 dB, może mix ogólnie jest zbyt głośny w wysokich tonach? W takim przypadku lepiej zmniejszyć wysokie tony na innych ścieżkach, zamiast zniekształcać ścieżkę wokalną… 😉
Krok 8: Saturacja (opcjonalnie)
To całkowicie opcjonalne, ale czasami może być interesujące dodanie saturacji harmonicznej.
Może to być saturacja maksymalna, aby wygenerować efekt specjalny typu zniekształcenie, ale domyślnie radzę pozostać przy bardziej subtelnych ustawieniach saturacji.
Idea polega na wzmocnieniu zawartości harmonicznej sygnału, aby dźwięk był nieco cieplejszy, nieco bardziej interesujący, nieco bardziej wyrazisty w mixie.
Zauważ, że ta technika nie jest specyficzna dla mixowania wokali: można ją zastosować do wszelkiego rodzaju instrumentów.

Oczywiście, jeśli nagranie zostało już wykonane z kolorowym przedwzmacniaczem (np. typu Neve), ponowne dodanie saturacji może nie przynieść wiele korzyści — a nawet zaszkodzić jakości mixu.
Natomiast, jeśli użyty przedwzmacniacz jest neutralny (co jest przypadkiem większości przedwzmacniaczy wbudowanych w karty dźwiękowe) lub ma tendencję do dawania raczej płaskiego brzmienia, to warto dodać trochę kosmetycznej saturacji, na przykład dzięki pluginom symulującym taśmy magnetyczne.
Kilka rekomendacji pluginów:
- Kazrog True Iron ;
- Waves J37 (-10% z tym linkiem i kodem, który się wyświetli) ;
- Soundtoys Radiator ;
- lub na przykład jeden z tych darmowych pluginów saturacyjnych.
Krok 9: Kompresja równoległa (opcjonalnie)
Oczywiście, wszelkiego rodzaju przetwarzania mogą być stosowane do wokali.
Cel tego artykułu nie polega więc na wymienianiu wielu istniejących możliwości — w przeciwnym razie po prostu zgubisz się wśród tych wszystkich informacji (mając na uwadze, że już jest ich dużo na tej stronie 🙂 ).
Jednak techniką zarówno bardzo praktyczną, jak i powszechnie stosowaną jest tzw. “kompresja równoległa” lub “kompresja nowojorska”.
Metoda ta polega na mocnym skompresowaniu identycznej ścieżki do podstawowej ścieżki wokalnej, a następnie subtelnym wymieszaniu jej z sygnałem oryginalnym.
To pozwala zachować szczyty i część dynamiki sygnału, jednocześnie wspierając “od dołu” najsłabsze dźwięki, co sprawia, że głos łatwo wyróżnia się w mixie w porównaniu do innych instrumentów.
Aby uzyskać więcej informacji, zapraszam do zapoznania się z moim poradnikiem na temat kompresji równoległej.
Krok 10: Reverb i Delay
Na koniec, ostatni krok często polega na umiejscowieniu głosu prowadzącego w przestrzeni stereo, w trzech wymiarach.
To znaczy, dodać reverb do swojej ścieżki wokalnej.
Domyślnie radzę robić to na końcu, aby uniknąć maskowania niektórych wad lub problemów w twoim mixie.
Na koniec mówię o reverbie, ale można również używać innych efektów, takich jak na przykład delay.
Po prostu, to zależy od stylów muzycznych i gęstości efektu, którego szukasz.
Reverb
Aby uczynić głos mniej suchym, dodanie wtyczki pogłosowej jest często najprostszym rozwiązaniem.
Rzeczywiście, ten efekt pozwala natychmiastowo uczynić głos bardziej interesującym, nadając mu wymiar stereo.
Minusem jest to, że im więcej pogłosu dodasz do głosu, tym bardziej będzie on wydawał się odległy:
Czas trwania pogłosu i jego względna głośność w porównaniu do ścieżki głosu będą więc dwoma krytycznymi parametrami, które musisz koniecznie opanować:
- zbyt długi pogłos zatopi sygnał podstawowy, a słowa będą mniej zrozumiałe;
- zbyt głośny pogłos da wrażenie oddalenia od źródła dźwięku.
W związku z tym, w przypadku niektórych nowoczesnych gatunków muzycznych, które wymagają bardzo frontalnego głosu w miksie, być może będziesz musiał zrezygnować z pogłosu.
Następnie, typ pogłosu również wpłynie na jego skuteczność w miksie.
Osobiście mam małą preferencję dla pogłosów płytowych (zwłaszcza Abbey Road Reverb Plates od Waves: -10% z tym linkiem i kodem, który się wyświetla) oraz dla niektórych pogłosów algorytmicznych (jak te od ValhallaDSP).
Ale oczywiście masz wolność eksperymentowania z wszystkimi dostępnymi wtyczkami.
Delay
Kiedy pogłos nie pasuje do nadania wymiaru ścieżce głosu, może być interesujące użycie efektu delay (lub echo po francusku, to to samo).
Może to wydawać się zaskakujące, ponieważ delay często postrzegany jest jako efekt specjalny, ale jest to efekt powszechnie używany podczas miksowania głosów.
Dokładniej mówiąc, wielu inżynierów używa techniki zwanej slapback delay — bardzo prostej, ale niezwykle skutecznej w nadawaniu głosowi głębi.

Konkretnie polega to na użyciu wtyczki delay ustawionej w następujący sposób:
- bardzo krótki czas echa (średnio 50-100 ms);
- jedno powtórzenie (więc ustawienie feedbacku na 0%);
- tylko mono (powtórzenie sygnału w kanale lewym jest identyczne z tym w kanale prawym).
Oczywiście, wyrównanie efektu echa jest konieczne, aby nie dominował on nad podstawową ścieżką.
Zapraszam do tego artykułu po więcej informacji na ten temat.
Gratulacje, teraz wiesz, jak miksować głos!
Na początek, gratulacje za dotarcie do końca tego długiego artykułu! 🙂
Teraz znasz etapy, aby skutecznie zmiksować głos lead, niezależnie od stylu muzyki czy nagrania (choć jakość twojego miksu będzie oczywiście zależała od jakości nagrania).
Teraz ostatni krok to po prostu praktyka: weź stary miks, usuń wszystkie efekty ze ścieżki głosu i zacznij miksować go, podążając za krokami tego artykułu.
Następnie zrób to samo z swoim następnym utworem.
Szybko zauważysz, że twoje ścieżki wokalne będą bardziej wyraziste i zajmą lepsze miejsce w miksie.
Na tym kończąc, do zobaczenia wkrótce w kolejnych artykułach o miksowaniu audio 🙂